 One of the most frustrating realities in experimental science is deceptively simple: running experiments is expensive. Synthesizing a new material, testing a drug candidate, or measuring a physical property can cost thousands of dollars and weeks of laboratory time. As a result, scientists often have only a few dozen data points to work with — far too few for conventional AI models, which typically need thousands or millions of examples to make reliable predictions.
One of the most frustrating realities in experimental science is deceptively simple: running experiments is expensive. Synthesizing a new material, testing a drug candidate, or measuring a physical property can cost thousands of dollars and weeks of laboratory time. As a result, scientists often have only a few dozen data points to work with — far too few for conventional AI models, which typically need thousands or millions of examples to make reliable predictions.
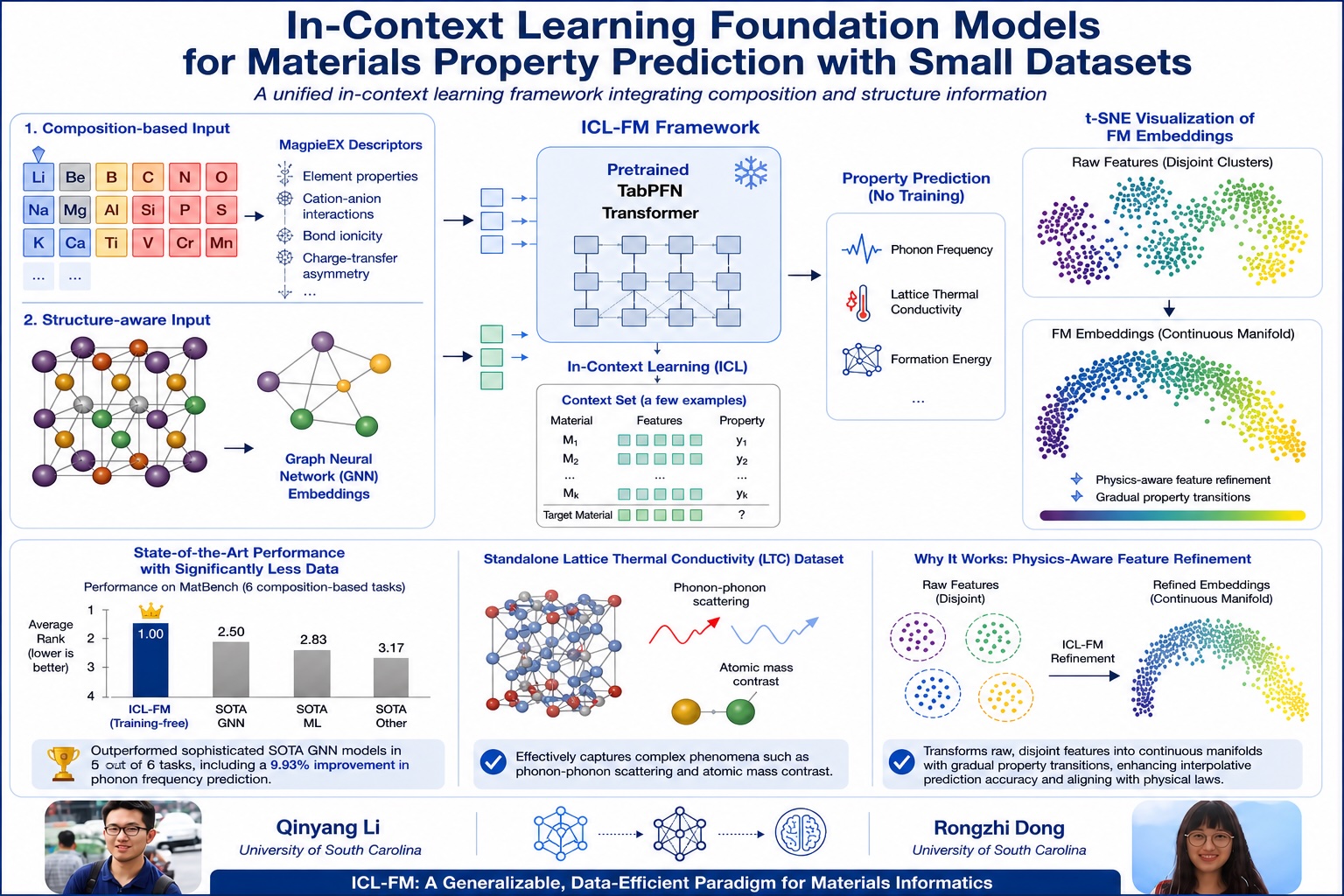
A new study from the University of South Carolina's Department of Computer Science and Engineering has found a way around this fundamental bottleneck. Published in npj Computational Materials — one of the world's top materials science journals from the prestigious Nature family of publications, with an impact factor of 9.5 — the research introduces a new AI framework called ICL-FM (In-Context Learning Foundation Model) that can predict material properties accurately even when trained on tiny datasets, and in many cases requires no training at all.
The Core Idea: Teaching AI to Learn from Context, Not Volume
The key insight borrows from how large AI systems like ChatGPT work. These so-called "foundation models" are pretrained on enormous amounts of general knowledge, then given a handful of relevant examples at the moment they need to answer a question — a technique called in-context learning. Prof. Jianjun Hu's team asked: could this same strategy work for scientific property prediction, where data is scarce by nature?
The answer, it turns out, is a resounding yes. ICL-FM combines a pretrained transformer model (TabPFN) with specialized representations of material chemistry, including a new descriptor system the team developed called MagpieEX. MagpieEX captures how atoms bond and exchange charge within a material — information critical for predicting properties like how well a material conducts heat or vibrates at the atomic level.
Outperforming Larger Models with Far Less Data
The results are striking. Tested on MatBench — the standard benchmarking suite for materials property prediction — ICL-FM matched or outperformed state-of-the-art graph neural network models on five out of six composition-based tasks, including a nearly 10% improvement in predicting phonon frequencies, which govern how heat moves through a solid. Crucially, it achieved this in a completely training-free mode: the model was never specifically trained on materials data at all.
The team also showed that ICL-FM's internal representations are physically meaningful. Rather than treating atomic features as disconnected data points, the model organizes them into smooth, continuous patterns that mirror real physical laws — a property the researchers confirmed using a visualization technique called t-SNE analysis.
Why This Matters Beyond Materials Science
The implications extend well beyond predicting how metals or crystals behave. The small-data problem is universal in experimental science.
In drug design, identifying which molecule will bind effectively to a disease target — without synthesizing thousands of compounds — is one of the field's hardest challenges. In chemistry, predicting how a reaction will proceed from limited experimental observations could dramatically speed up catalyst development for clean energy. In physics, characterizing exotic quantum materials requires painstaking measurements that yield only sparse datasets. In each of these fields, an AI system that performs well with limited data is not just convenient — it is transformative.
ICL-FM's architecture is built to generalize. The same framework that predicts thermal conductivity in crystals today could, with appropriate material representations, be adapted to molecular property prediction in pharmaceuticals, reaction yield prediction in synthetic chemistry, or property forecasting in semiconductor design.
A New Paradigm for Materials Informatics
"This work establishes a new paradigm for data-efficient AI in materials science," said Prof. Jianjun Hu, the study's corresponding author and a faculty member in USC's Department of Computer Science and Engineering. The research was supported by the National Science Foundation.
The study's first authors, Qinyang Li and Rongzhi Dong, are PhD students in the department, alongside co-authors Nicholas Miklaucic, Sadman Sadeed Omee, Lai Wei, and Sourin Dey. The team also collaborated with Jeffrey Hu from the University of Illinois Urbana-Champaign and Prof. Ming Hu from USC's Department of Mechanical Engineering. This research was funded by the National Science Foundation.
The paper is open access and freely available at nature.com.